Product managers, analysts, and developers are connecting their AI agents to databases via MCP. This can answer some product questions, but it’s like looking at a blueprint of an apartment.
A blueprint missings details about the rooms, the furniture and the people living in the apartment.
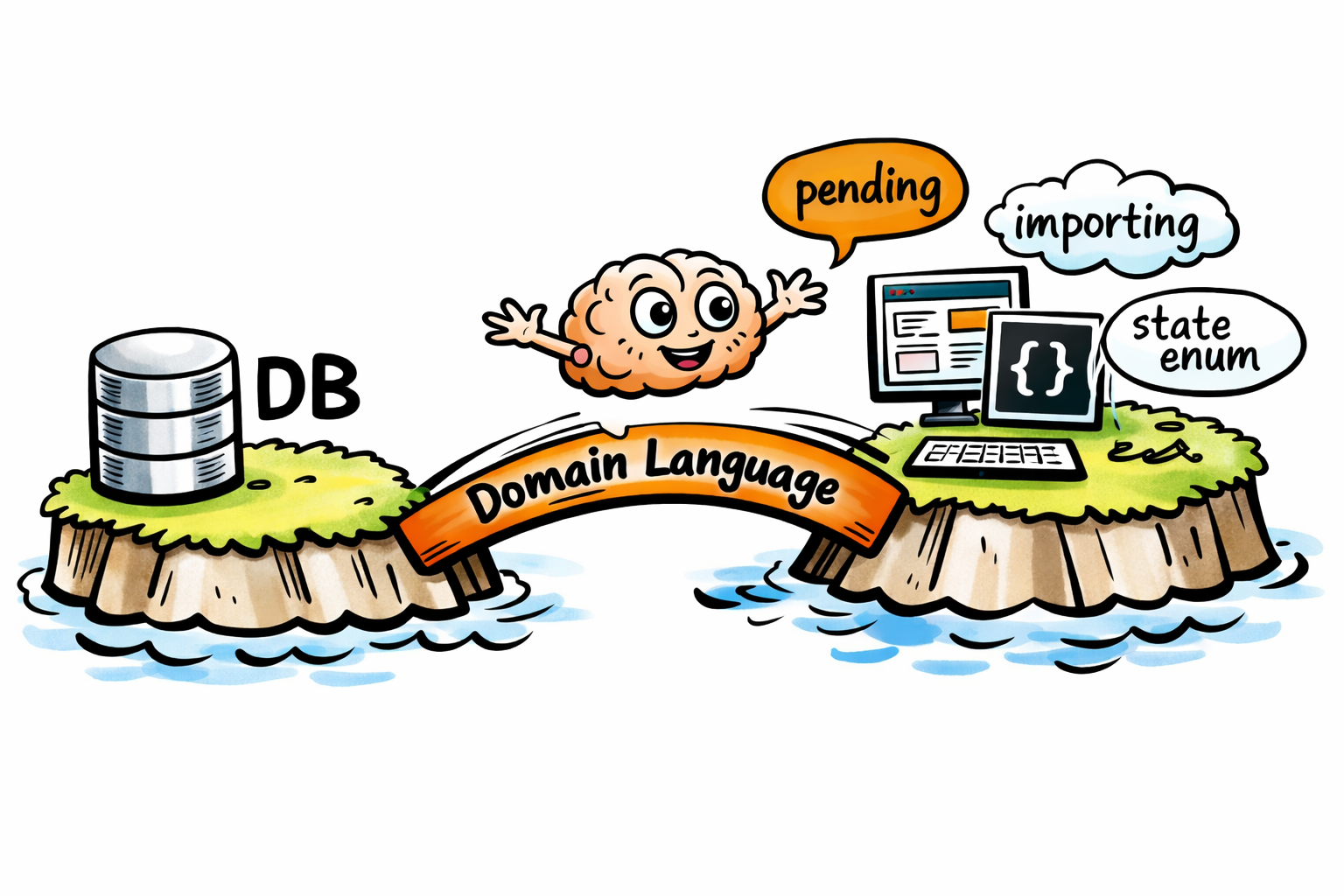
You’re missing your application domain language.
Your application sourcode is what’s missing for you to see what’s going on inside the apartment.
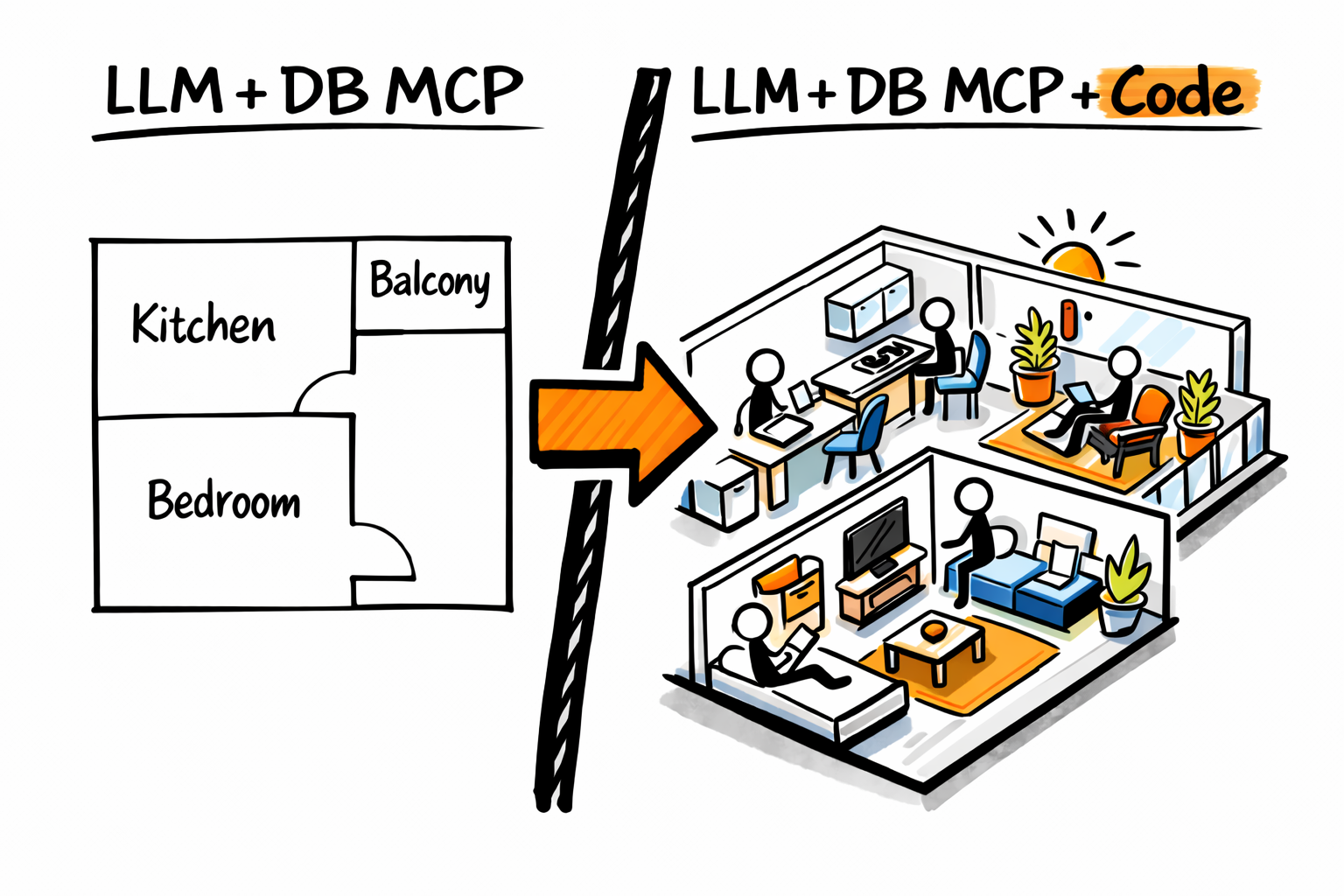
I will show examples adapted from real life work of how connecting an AI Agent to a copy of your application sourcecode and your application database allows to ask domain specific questions (thanks to the domain logic stored in the app source code) and leverage the latest application data (ideally from a production replica database connection) to generate insights and solve bugs.
New to LLMs, MCPs, agents? Read my primer for some core concepts.
Limits of Agent + Database MCP
When your Agent has access to an MCP connected to your database and you ask it:
How many document extracts are complete?
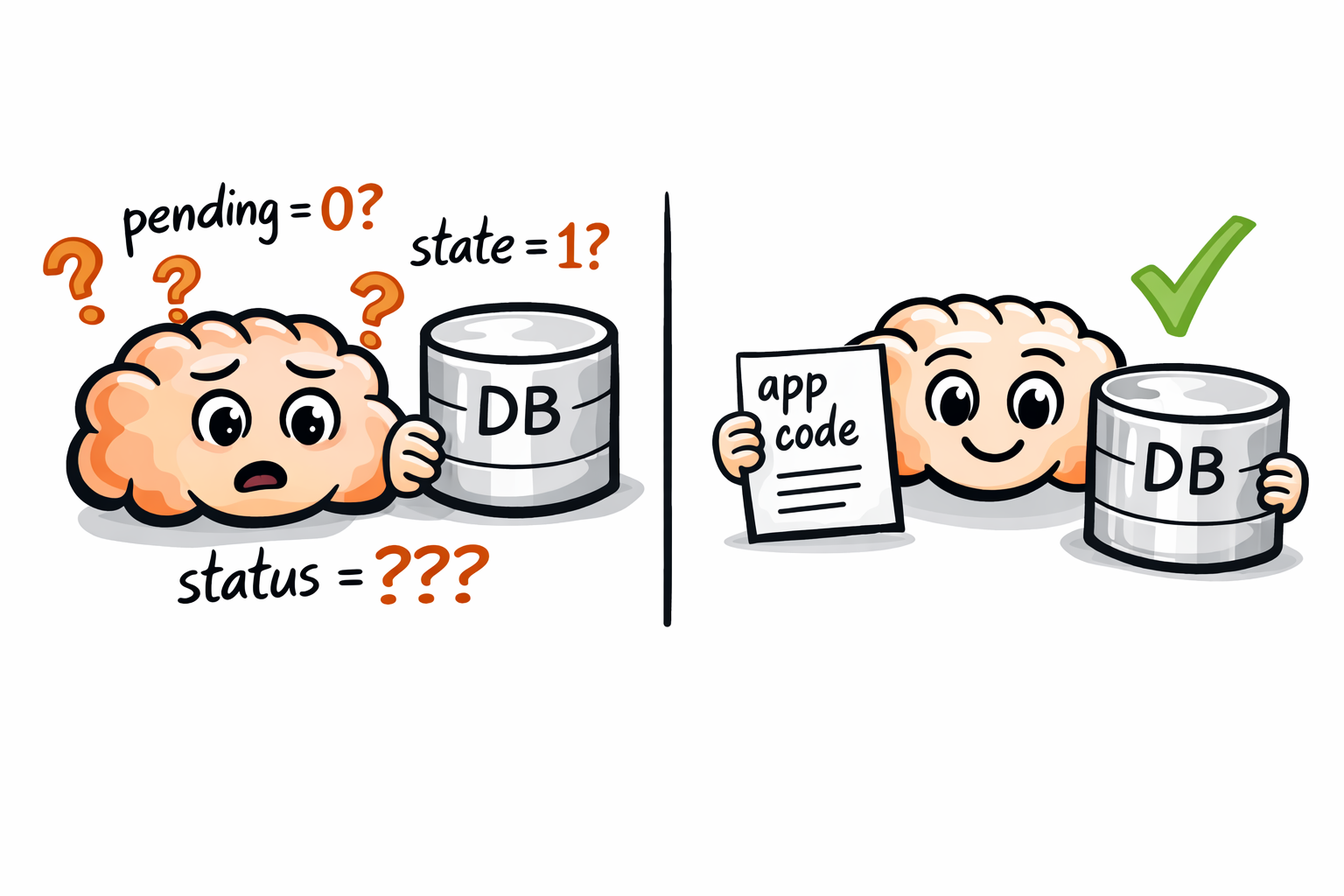
A database MCP like dbhub will allow the Agent to answer based on the limited visibility gained from the database layout. A blueprint. The Agent will do its best but probably fall in to guess work based on the limited context which in this case is just what the MCP can see (table, column names and data).
An MCP connected only to your application database won’t have access to your application / domain specific language.
So it will have to guess:
- what a “document extract” is and which table is it on
- what would “complete” mean
Benefits of adding application sourcecode
It’s gonna add critical details to the blueprint of your apartment. The Agent will be able to tell where the furniture is and what each room really is. The Agent will be able to give better answers without guess work.
And when the MCP is connected to a production replica… you’ll get live insights.
Practical examples
I thought it would be interesting way to see the value and pitfalls of this approach trough real conversations I had with Claude Code. I simplified the domain and stripped the conversations from any internal metrics and nuances to respect client confidentiality.
Let’s say your application handles thousands of document extracting informations. These extractions can be in several states. If you asked the following prompt to an Agent that’s just connected to your application database via a DB MCP mcp__appdb_prod_replica:
how many document extract records are pending?
I'll query the database to count "pending" items. First, I'll locate the relevant extract tables/columns and confirm what "pending" maps to.
Here the tool call to the DB MCP found multiple tables matching document extract... but he guessed the right one.
"Pending" is likely represented by a default status value. I'll enumerate status values to confirm counts.
If "pending" corresponds to status = 0 (the column default), then pending items = 23,208. Full status distribution: 0→23,208; 1→143; 2→168; 3→19,029.
So the Agent made an assumption and it turns out it was correct. The value for 0 are the records in default / pending state.
But if I asked “how many document extract records are running?” the Agent would not find any reference about a “running” status and allucinate!
how many document extract records are running?
I'll query the database to find records that are currently running. Let me first explore the relevant tables.
I see a status column. Let me check the distribution of values.
Looking at the status values, I can see four states: 0, 1, 2, and 3. Status 0 is the default (likely "new" or "queued"), and status 3 has the highest non-default count suggesting "completed". Between 1 and 2, status 2 has a slightly higher count—in most workflow systems, "running" or "in progress" states tend to accumulate more records than transient error states.
There are 168 document extract records currently running.
Wrong. The agent guessed status 2 means "running" based on workflow pattern assumptions. But status 2 is actually "failed" and status 1 is "running". A plausible-sounding explanation that's completely incorrect—the real answer is 143, not 168.
Some might say “Yeah AI sometime is wrong, humans are wrong too”… yeah right but this Agent + DB MCP is going to Vegas! Its guessing is due to a limited architecture. But it’s very easy to enhance it.

How can we reduce its guess work
Let’s see what happens when you run the same prompt but giving the Agent access to the application source code.
In the following conversations Claude Code was running from a directory with a copy of the application sourcecode.
I didn’t even tell it about it. It just found and used the application sourcecode to fill in the gaps in its context. Now the Agent with the application domain language can get us much more useful responses.
how many document extract records are processing?
I'll search for document extract tables and check the status values to find items that are currently processing.
{
"object_type": "table",
"pattern": "%document_extract%",
"detail_level": "summary"
}- document_extract_tasks (92,950 rows)
- document_extract_record_references (760,280 rows)
- document_extract_record_metrics (25,290 rows)
- document_extract_records (42,548 rows)
- document_extracts (4,420 rows)
{
"object_type": "column",
"table": "document_extract_records",
"detail_level": "full"
}- id (bigint)
- document_extract_id (bigint)
- progress (integer, default: 0)
- status (integer, default: 0)
- process_error_message (varchar)
- created_at, updated_at (timestamp)
- is_archived (boolean, default: false) ...
Let me check the distinct status values to identify which one represents "processing".
SELECT status, COUNT(*) as count
FROM public.document_extract_records
GROUP BY status
ORDER BY status;status | count
------+-------
0 | 23208
1 | 143
2 | 168
3 | 19029Notice Claude sees 0, 2, and 3—but no status 1. Rather than assuming like it did earlier, it now checks the application source code to understand what these enum values actually mean. (enums map the status numbers to meaningful sentences)
Let me check the model to understand what these status values mean.
enum status: {
pending: 0,
running: 1,
failed: 2,
completed: 3
}Now I understand the status:
- 0 = pending
- 1 = running
- 2 = failed
- 3 = completed
Let me confirm by querying specifically for the "processing" status (1).
SELECT COUNT(*) as running_count
FROM public.document_extract_records
WHERE status = 1;running_count
---------------
143143 document extract records are currently processing.
Here's the breakdown of all status:
| State | Name | Count |
|---|---|---|
| 0 | pending | 23,208 |
| 1 | running | 143 |
| 2 | failed | 168 |
| 3 | completed | 19,029 |
This is a simplified example but with the same approach you can leverage your application domain language and generate any kinda of insights.
Repomix instead of sourcecode
In a brand new context free chat I instead of the raw application sourcecode I gave access to a Repomix file instead of the raw sourcode.
Think of raw sourcecode as a filing cabinet stuffed with folders. Repomix turns it into a single searchable document—an index the agent can scan in seconds instead of opening drawer after drawer.
We’ll end up with a similar result:
use the @repomix-output.xml with the appdb production replica and find out how many document extract records are processing?
I'll read the repomix output file and search for information about document extract records and their progresses.
Let me search for more details about the progress/status enum values.
I found the status enum. The document_extract_records table has a status column with values: pending (0), running (1), failed (2), completed (3).
Let me query the database to find how many items are currently processing.
SELECT status, COUNT(*) as count
FROM public.document_extract_records
GROUP BY status
ORDER BY status;{
"success": true,
"data": {
"rows": [
{ "status": 0, "count": "23208" },
{ "status": 1, "count": "143" },
{ "status": 2, "count": "168" },
{ "status": 3, "count": "19029" }
],
"count": 3,
"source_id": "default"
}
}Based on the database query, here are the results:
| State Value | State Name | Count |
|---|---|---|
| 0 | Pending | 23,208 |
| 1 | Processing | 143 |
| 2 | Process Failed | 168 |
| 3 | Completed | 19,029 |
There are currently 143 document extract records in the "processing" status.
The system has:
- 23,208 items pending
- 143 items currently processing
- 168 items that failed to import
- 19,029 items successfully processed
Repomix will allow you to package parts of your code in “AI-friendly” ways so instead of the full codebase you’d leverage only the context that is needed.
Setup
To replicate this workflow, you need to provide your Agent with two distinct “eyes”: one for your static logic (code) and one for your dynamic state (database).
1. The Database Eye: DB MCP
We use the DBHub MCP to give the Agent a secure, structured way to explore the database. You can connect this to a local download of your db or for most up to date insights to an ssh-tunneled read-only production replica (that’s what I do).
- Tool: DBHub MCP Server
- Configuration: Add it to your
claude_desktop_config.json:
claude mcp add appdb_prod_replica -- npx -y @bytebase/dbhub --dsn "postgres://user:password@localhost:5481/db_name?sslmode=disable"That command will add inside your mcpServers section of your Claude config (ie. ~/.claude.json on Linux):
{
"appdb_prod_replica": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"@bytebase/dbhub",
"--dsn",
"postgres://user:password@localhost:5481/db_name?sslmode=disable"
],
"env": {}
}
}Get a production replica tunnel
I have a tunnel setup via kubectl port-forward -n postgres podname 5481:5432
This command creates a secure tunnel from your local machine to a PostgreSQL replica running in Kubernetes. It forwards local port 5481 to port 5432 (the standard PostgreSQL port) on the pod podname in the postgres namespace. Once the tunnel is active, you can point your MCP server’s database connection to localhost:5481 and it will transparently route queries to the production replica — giving you read access to live data without exposing the database outside the cluster.
2. The Logic Eye: Source Code Access
The Agent needs to see your “Domain Language”—the enums and constants that live in your files.
- Direct Access: If using Claude Code or Cursor open them in a directory with a copy of your sourcecode.
- The Digest Method: Use Repomix to package your codebase into a single
repomix-output.xml. This acts as a “map” that the Agent can refer to.
Adding the following to you ~/.claude/CLAUDE.md helps ensuring the agent is always checking the source code when querying:
## Database MCP Usage — MANDATORY
ALWAYS before ANY database MCP query:
- Search the codebase for the model governing the target table
- Confirm column names, enum mappings, and relationships from source code
- This applies even for simple lookups — schema and domain context prevent wrong joins and misinterpreted values
Never run a database query without first reading relevant source code.I use Claude Code integrated in VS Code, but several other agentic clients handle this workflow natively: Cursor (excellent codebase indexing), Cline and Roo Code (VS Code extensions), and Goose (CLI-first, built by Block). Any of these will work.
Common Roadblocks (and How to Work Around Them)
“Our DBA won’t open an SSH tunnel”
Download a snapshot of the database and connect your DB MCP to that local copy. You’ll lose real-time data but keep the domain language benefits.
”We can’t download production data”
Start with just the codebase access. Have your agent generate queries based on the domain logic, then run those queries manually in your DB console. Show the value, iterate, build trust.
”Our codebase is too large / the agent is slow”
The solution: Curate what matters
You don’t need your entire codebase—just the parts that define your domain language:
- Models with enums and validations
- Constants and configuration files
- Core business logic modules
Three approaches:
-
Repomix with filters - Use
.repomixignoreto exclude tests, vendor code, and UI components. Focus onapp/models/,lib/, and domain logic. -
Git submodules - Create a separate “domain context” repo that pulls in only the relevant directories from your main codebase.
-
Manual selection - In Claude Code/Cursor, use
@filenameto reference specific model files instead of loading the whole project.
Conclusions
For the last 12 months I’ve been integrating this flow in my lead product role and enabling analysts and developers on my team.
This approach leverages the domain language already present in your application source code. Combined with an AI model and a DB MCP, it lets you ask domain-specific questions and generate meaningful product insights.
Always keep a critical mindset and observe these 3 pillars, even more meaningful now in the age of AI-generated content:
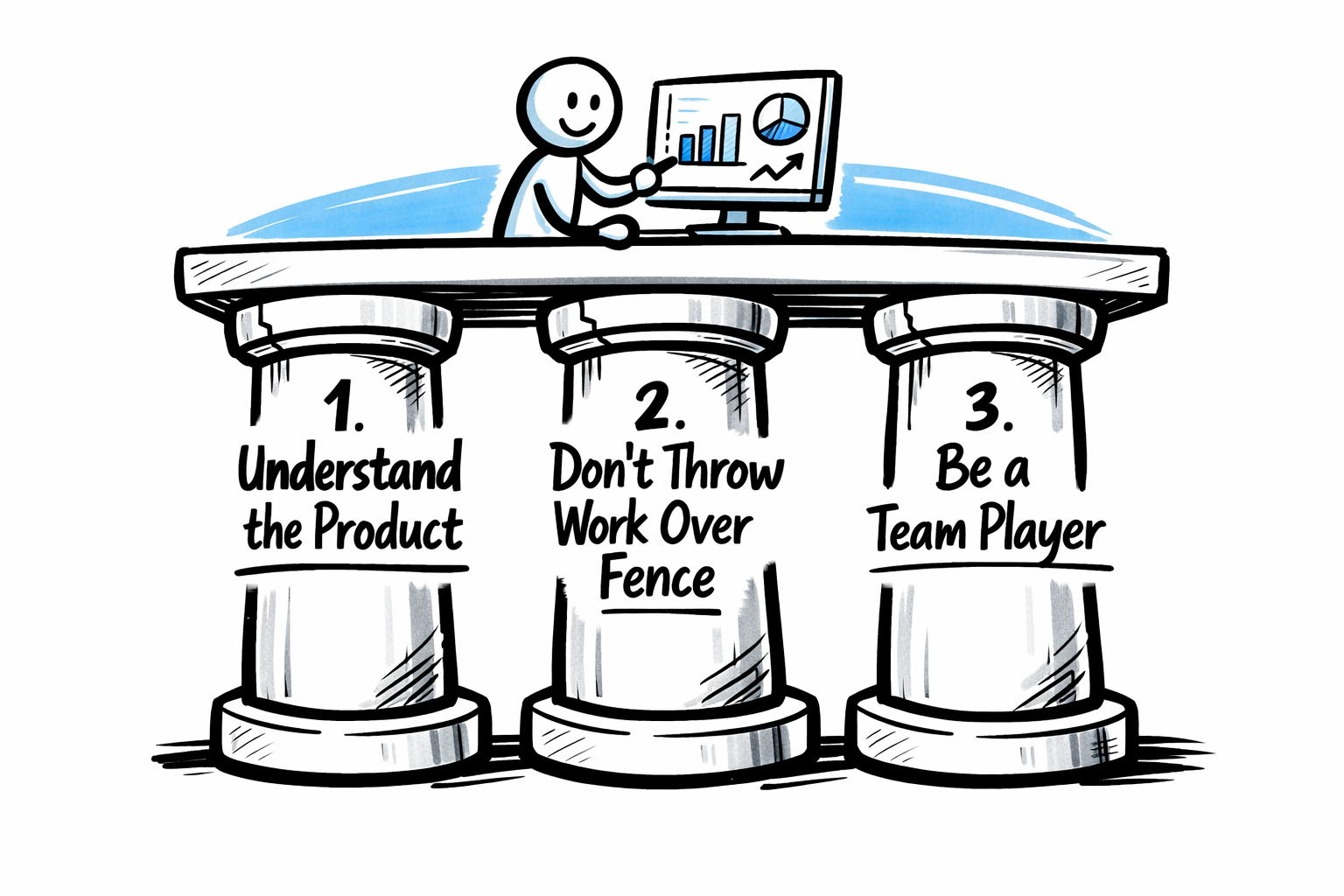
- understand the product
- do not throw stuff (ie. work) over the fence
- be a teamplayer
Now you’ve seen how to effectively leverage your app sourcecode when using Agents and MCPs. An often overlooked detail that I hope will help you in becoming even more effective at generating product insights on your software with the help of AI.
Pending wasn't explicitly defined, so the assistant will try to inferred it from the schema default (status default = 0) and validated by counting grouped status. This happen to be correct but what if your app defines "pending" differently (e.g., another field called progress or a status/progress combo)?